
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
Tags
- dbeaber
- 코딩
- 조인
- 인덱스
- Oracle
- 데이터분석
- S3
- dfs
- 자료구조
- Join
- snowflake
- HackerRank
- 율코딩
- 개발
- 백준
- 쿼리
- DB
- 데이터베이스
- 오라클
- 백트래킹
- 결합인덱스조건
- storage_integration
- sql
- Index
- AWS
- 문제풀이
- 결합인덱스란
- MySQL
- 알고리즘
- 인덱스튜닝
Archives
- Today
- Total
율코딩
[Oracle] Sort Merge Join / Hash Join 본문
반응형
소트 머지 조인 (Sort Merge Join)
소트머지 조인은 두 테이블을 각각 조건에 맞게 먼저 읽는다.
그리고 읽은 두 테이블을 조인 컬럼을 기준으로 정렬해놓고, 조인을 수행한다. 주로 조인 조건 칼럼에 인덱스가 없거나, 출력해야 할 결과 값이 많을 때 사용된다.
NL 조인을 효과적으로 수행하려면 조인 컬럼에 인덱스가 필요한데 만약 적절한 인덱스가 없다면 Inner 테이블을 탐색할 때마다 반복적으로 Full Scan을 수행하므로 매우 비효율적이므로 그럴 때 옵티마이저는 소트 머지 조인이나 해시 조인을 고려한다.
오라클에서는 정렬을 하게 되면 PGA라는 공간에서 정렬을 수행하게 되는데, PGA 공간은 프로세스에 할당 된 독립된 공간이기 때문에 버퍼 캐시(SGA영역)를 사용하는 NL 조인에 비해 조인을 시도하는 데이터 접근이 보다 빠르게 수행된다.
아래와 같은 SQL문이 있다고 하자.
SELECT /*+ ORDERED USE_MERGE(B) */
A.*
, B.*
FROM ITEM A
,UITEM B
WHERE A.ITEM_ID=B.ITEM_ID -- 1
AND A.ITEM_TYPE_CD = '100101' -- 2
AND A.SALE_YN = 'Y' -- 3
AND B.SALE_YN = 'Y' -- 4
ITEM_X01 -> ITEM_TYPE_CD UITEM -> 없음
Q. 소트 머지 조인으로 조인을 한다고 할 때, 해당 SQL문에서 동작 순서는 어떻게 될까?
정답은 2 -> 3 -> 4 -> 1 이다.
그 이유는 아래의 그림을 통해 좀 더 쉽게 설명할 수 있다.

실행 순서
- A 테이블에서 인덱스 ITEM_X01를 통해 ITEM_TYPE_CD = 100100인 것을 스캔하고 SALE_YN = 'Y'인 필터조건을 맞는 데이터를 찾는다.
- B 테이블에서 SALE_YN = 'Y' 에 해당하는 데이터를 찾기 위해 Table Full Scan으로 읽는다.
- PGA 공간에서 조인컬럼을 기준으로 정렬을 수행한다.
- 두 테이블을 조인한다.
소트 머지 조인 특징
- PGA영역에 저장된 데이터를 이용하기 때문에 빠르므로 소트부하만 감수하면 NL조인보다 유리하다.
- 인덱스유무에 영향을 받지 않는다.
- 스캔위주의 액세스방식을 사용한다.
(단, 양쪽 소스 집합에서 정렬 대상 레코드를 찾는 작업은 인덱스를 이용해 Random엑세스 방식으로 처리, 이 때 액세스량이 많다면, 소트머지 이점이 사라질수 있음) - 대부분 해시조인인 보다 느린 성능을 보이나, 아래와 같은 상황에서는 소트머지 조인이 유용하다.
- First테이블에 소트연산을 대체할 인덱스가 있을 때
- 조인할 First 집합이 이미 정렬되어 있을 때
- 조인 조건식이 등치(=)조건이 아닐 때
- 두 결과 집합의 크기가 많이 차이나는 경우에는 SORT MERGE JOIN이 비효율적이다.
- 어느 한 쪽이라도 정렬 작업이 종료되지 않으면 조인이 시작될 수 없으므로 두 테이블 조인 집합의 크기가 많이 차이가 난다면 한쪽에 '대기' 상태가 발생하여 비효율적으로 처리가 된다. 이렇게 크기가 비슷하지 않은 집합의 조인을 위해서 HASH 조인을 사용할 수 있다.
성능 개선 포인트
ACCESS 하는 속도를 향상
- 테이블을 Access 할 때 FULL TABLE SCAN이냐 INDEX RANGE SCAN이냐 하는 등 테이블을 Access 하는 방법을 다양한 방법을 통해 최적화시킨다면 SORT MERGE JOIN의 속도도 자연스럽게 최적화할 수 있다.
정렬 속도의 향상
- SORT MERGE JOIN은 양쪽 테이블에서 조회한 데이터들을 정렬시켜야 한다. 이때 조인 조건 컬럼이 이미 정렬되어 있다면 정렬을 하는 작업을 단축시켜 검색 속도 향상에 도움이 될 것이다.
양쪽의 정렬 완료 시점 맞추기
- SORT MERGE JOIN은 양쪽 테이블을 ACCESS하고 조회한 데이터들을 정렬할때 어느 한쪽이라도 정렬 작업이 종료되지 않으면 한쪽이 대기 상태가 되고 다른 한쪽의 정렬이 완전히 끝날 때까지 조인이 시작될 수 없다. 그렇기에 두 테이블 ACCESS속도와 정렬 속도를 최대한 비슷하게 맞추어주는 것이 좋다.
SORT_AREA_SIZE 최적화
- SORT MERGE JOIN은 두 테이블 간의 비교가 이루어지기 전에 수행하는 정렬 작업을 위해 별도의 정렬 공간이 필요하며 이 공간은 SORT_AREA_SIZE 크기만큼 메모리를 할당받아 사용하게 되고, 메모리가 부족하다면 Temporary Table Space를 이용하여 정렬을 수행하게 된다. 이때 Temporary Table Space를 사용하면 딜레이가 생기므로 SORT_AREA_SIZE를 적당한 크기로 설정해두는 것이 속도 향상에 도움이 된다.
해시 조인 ( Hash Join )
HASH 조인은 조인될 두 테이블 중 하나를 해시 테이블로 선정하여 조인될 테이블의 조인 키 값을 해시 알고리즘으로 비교하여 매치되는 결과값을 얻는 방식입니다.
HASH JOIN은 비용 기반 옵티마이저를 사용할 때만 사용될 수 있는 조인 방식이며 '=' 비교를 통한 조인에서만 사용될 수 있습니다. 주로 많은 양의 데이터를 조인해야 하는 경우에 주로 사용됩니다.
HASH JOIN의 사용 케이스
- JOIN 컬럼에 적당한 인덱스가 없어 NL JOIN이 비효율적일 때
- JOIN Access량이 많아 Random Access 부하가 심하여 NL JOIN이 비효율적일 때
- Sort Merge Join을 하기에는 두 테이블이 너무 커 Sort 부하가 심할 때
- 수행빈도가 낮고 쿼리 수행 시간이 오래 걸리는 대용량 테이블을 JOIN 할 때
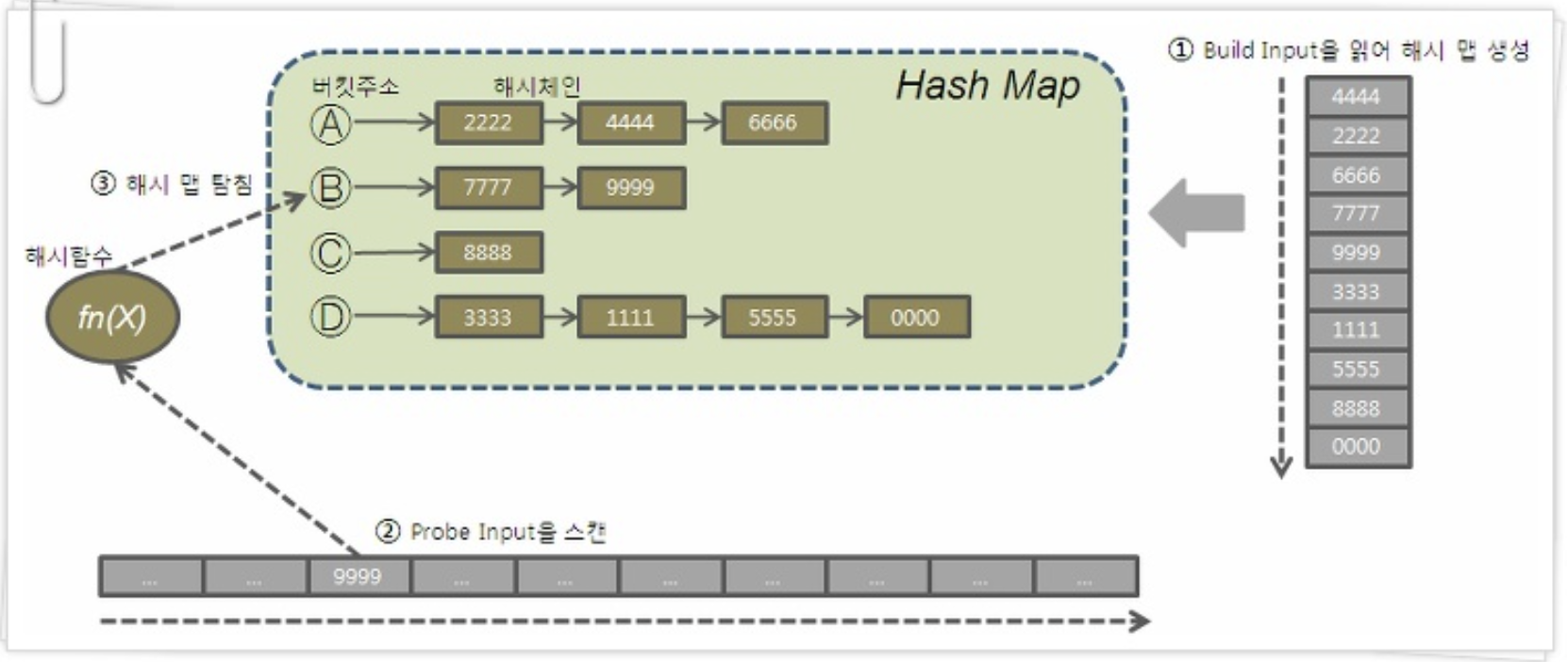
- 둘 중 작은 집합(Build Input)을 읽어 Hash Area에 해시 맵을 생성한다. (해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인에 엔트리를 연결)
- 반대쪽 큰 집합(Probe Input)을 읽어 해시 맵을 탐색하면서 JOIN 한다.
- 해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인을 스캔하면서 데이터를 찾는다.
성능 개선 포인트
- 해시 맵으로 만들 Build Input이 Hash Area에 담길 정도로 충분히 작아야 한다.
- Build Input 해시 키 칼럼에 중복 값이 거의 없어야 효율적인 동작을 기대할 수 있다.
- 충분한 PGA 메모리 확보
- Hash Area는 PGA 메모리에 할당되는데 Build Input이 HASH_AREA_SIZE를 초과하게 되면 가장 큰 순서대로 Hash Bucket이 Temporary Table Space로 내려가서 구성됩니다. 디스크로 내려간 Hash Bucket에 변경이 일어날 때마다 디스크 I/O가 발생하게 되어 성능이 현저하게 저하된다.
반응형
'데이터베이스' 카테고리의 다른 글
| [오라클] 인덱스 클러스터링 팩터 (0) | 2022.10.02 |
|---|---|
| [오라클/MySQL] 트랜잭션 수준 읽기와 격리 수준 (Isolation Level) (5) | 2022.08.20 |
| [JOIN] NL Join (Nested Loops 조인) (1) | 2022.07.09 |
| [DB] 결합인덱스 및 컬럼 순서 결정 방법 (0) | 2022.06.05 |
| Index를 타지 않는 Query (1) | 2022.06.05 |
'데이터베이스' Related Articles
more

